

投资者权益保护法如何规范证券市场的交易行为
投资者权益保护法,特别是《证券法》,通过一系列具体规定来规范证券市场的交易行为,以保护投资者的合法权益。这些规范主要包括以下几个方面: 1. 行为规范: 证券法对证券市场的参与主...

免疫系统如何影响肺部结节
1. 免疫监视与防御:免疫系统通过识别并清除体内的异常细胞,包括可能发展成肿瘤的细胞。在肺部,免疫细胞如T细胞和自然杀伤细胞(NK细胞)持续巡逻,监视任何潜在的病原体或异常增生的细...

使用充电宝时需要注意什么
1. 避免挤压和摔打 :充电宝在携带或存放过程中,应避免受到重压、摔打或强烈震动,以免内部电路受损或短路,导致起火或爆炸。 2. 控制充电时间 :充满电后应及时拔掉电源,避免长时间过充...

excel表格如何一键调整行高? excel表格一键调整行高方
大家好!今天来给大家普及一下Excel表格的一个小技巧——如何一键调整行高。相信很多小伙伴在使用Excel时都曾遇到过需要调整行高的情况,有时候一列数据多了,行高不够显示怎么办呢?别担心...

Word中如何设置字体样式和大小
在Word中设置字体样式和大小,可以通过以下几种方法实现: 方法一:使用字体组和快捷键 1. 打开Word文档,并选中你想要更改的文字。 2. 在“开始”或“主页”选项卡中找到“字体”组。 3. 点击...

如何关闭三星手机的设备位置共享
1. 进入三星手机的设置界面 :从手机主屏幕上找到“设置”图标,并点击进入。 2. 寻找定位服务选项 : 在设置界面中,滑动屏幕找到并点击“定位服务”或“位置信息”选项。 另一种方式是通...

企业注销后的财务账务如何结算
企业注销后的财务账务结算是一个涉及多个法律环节的过程,需要遵循《中华人民共和国公司法》的相关规定。以下是详细步骤: 需要成立清算组并启动清算程序。公司因解散事由出现后,应当在...

投影仪与DVD连接时如何进行音频同步
1. 检查设备接口:首先确认您的DVD播放器和投影仪的接口类型。大多数现代设备都配备HDMI接口,这是传输音视频信号的最佳选择。 2. 使用HDMI线:如果两者都有HDMI接口,最直接的方法是使用一根...

社群与粉丝的关系如何平衡
社群与粉丝的关系的平衡是一个关键性的运营任务,以下是一些核心策略: 要明确社群和粉丝的本质区别与联系。社群是弱中性化的,更注重群体间的互动与交流;而粉丝则是有明显中性化的,他...

使用公共Wi-Fi时如何保护QQ账号
在使用公共Wi-Fi时,保护QQ账号的安全性是一个重要的问题。以下是几种有效的措施: 1. 避免在公共Wi-Fi下登录敏感账户 :公共Wi-Fi网络通常缺乏安全保护,容易被黑客利用进行中间人攻击(Man-i...

如何在微信中找到超级会员的功能
1. 绑定QQ超级会员 :如果你希望在微信中使用QQ超级会员的特权,可以关注QQ会员公众平台,然后点击【我的】->【绑定QQ】。这样,你就可以将QQ超级会员与微信账号绑定,享受更多特权。 2. 微信...

如何通过快捷键快速访问设置菜单
1. Windows系统 : 在Windows 10和Windows 11中,可以通过按下`Win + I`(Windows键 + I键)来快速打开设置菜单。 在Windows 11中,还可以使用`Win + A`快捷键打开快速设置菜单,然后从其中选择“设置”。 2. Ma...

怎么设置微信群头像、微信如何改群头像
本文目录一览: 1、 微信怎么设置群头像 2、 微信如何改群头像? 3、 怎么改微信群头像 如何改微信群头像 4、 怎样更换微信群头像? 5、 微信群头像怎么设置? 微信怎么设置群头像 打开微信:确保...

如何通过心理咨询帮助父亲应对失落感
要帮助父亲应对失落感,心理咨询可以发挥重要作用。以下是几种通过心理咨询帮助父亲应对失落感的方法: 1. 表达和接受情感 :心理咨询师可以帮助父亲表达对失去亲人的悲伤和内疚感。在咨...

如何判断飞利浦W626是否需要更换电池
1. 外观检查 :检查电池外壳是否有损坏或液体泄漏。如果发现电池外壳有损坏或液体泄漏,应及时更换电池。如果电池桩头松动严重,或者电池壳体鼓包严重,也表明电池可能需要更换。 2. 续航...
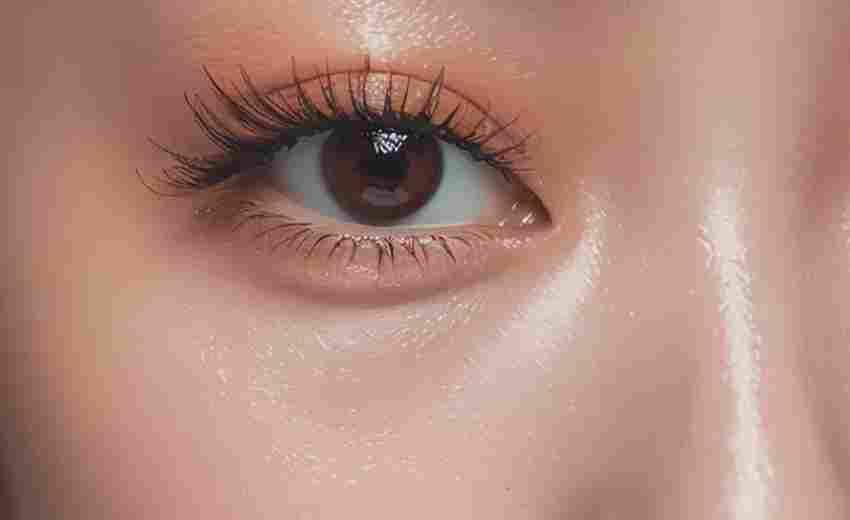
浅双眼皮如何避免眼妆看起来过于单调
1. 使用浅色眼影打底 :选择浅棕色、米白色或杏色等浅色眼影作为眼部打底,可以增加眼部的立体感和层次感,避免眼睛显得平淡无神。 2. 强调卧蚕和下眼睑 :在下眼睑的中段或卧蚕处使用珠光...

使用手机相机时如何设定拍摄尺寸
设定手机相机的拍摄尺寸,通常涉及调整照片的分辨率和比例,这可以让你根据拍摄需求来优化图片质量或文件大小。以下是根据参考内容整理的步骤和建议: 1. 打开相机设置:在手机上打开相机...

如何评估目标学校的专业排名
评估目标学校的专业排名是一个复杂且多维度的过程,需要综合考虑多个因素。以下是一些详细的步骤和建议: 1. 明确个人需求 :你需要明确自己的职业规划和兴趣方向。如果你对未来有明确的...

如何避免滴滴快车账号被盗
1. 定期修改密码:设置复杂且独特的密码,包含大小写字母、数字和特殊字符,并定期更换。避免使用生日、电话号码等容易被猜测的信息。 2. 启用二次验证:开启账户的二次验证功能,如短信验...

如何找到合适的合伙人共同创业
1. 确定合伙人的标准 相互信任:信任是基础,确保你们能彼此信赖,支持对方的决策。 共同价值观与愿景:确保你们对公司的未来有相似的看法,能够共同面对挑战。 理智决策:在分歧中能以公...